

It's been a long time since my last post : I've been quite busy at home and at work and could not continue my Talend development.
My last post left us with a simple flow that gave the highest ROI card for dCity, but it still missed some important stuff, like the technology cards and the taxes. This time I'll implement the technology cards.
@cocaaladioxine/finding-the-card-with-the-highest-roi-for-dcity-automated-
The highest APR card today is...
For those who don't want to read all the technical details :

The nuclear plant is the winner today with a 652% APR. But a strong negative popularity effect !! And it does not take the taxes into account. That's for the next post !
dCity Technology cards
There are several technology cards in dCity. Some of them give global boosts, while other focus on specific buildings. We don't need the global boosts for our calculations. Only the ones giving a boost to buildings are of interest.
As I mentionned in my previous post, I found card descriptions and id's in the dCity front-end code. Altough, the technology boosts are not mentionned.
Creating a technology cards referential
Still, the different tech cards are in the listing along their id and name, so I first extracted them into an Excel file (for ease of use). As there's only 33 cards, I decided to fill the table by myself.

- The blue column is the card id which will allow me to join the data with the API response
- The green column is the id of the card that gets a boost
- The yellow columns indicates the boost or reduction on each parameter (population, income,...)
- The grey column is there only for Advanced Prayer, which can be stacked up to 10 times
I filled the yellow, grey and green columns by myself.
Compute the tech boosts

I first need to compute to tech boost, then I'll feed it to the job I created for the previous post.
tRestClient : Call dCity Api player stats
This steps is almost the same as the Call dCity API market_cards, but it calls https://api.dcity.io/stats?user=cocaaladioxine .

I could simply pass the whole path in URL, but for demonstration purpose I used the "query parameter" to pass my user name.
tExtractJsonFields : Get active cards

Same as last time, but there is no actual loop needed: it just retrieves the $.last.active_cards in the response.

It's a simple list of all my cards with the amount I own. I'll handle it a bit differently though. I could use the same process as before, rewriting the list to transform the card_id into a value. It's so simple here, that I don't need it.
tReplace : unformat json
This steps removes the curly braces around the string, as well as the double quotes.

The active card list is now a one row flow, containing a single string looking like this :
1_basic: 28, 1_lux: 178, 2_uni: 16,2_ada_a: 30,2_ada_c: 3,2_sch: 75
So far nothing new.
tNormalize - Split line to rows
A good database design stores one data point per row. Not many. In python or json, a list is one entity holding many value. A relational database don't like this. Talend has a component that allows you to normalize or denormalize data.
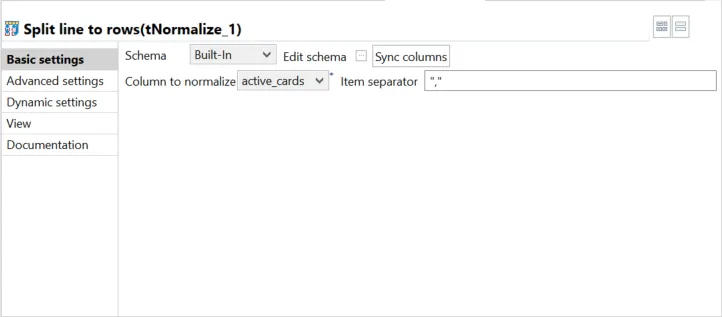
That's a very simple component. It only needs the field which will be denormalized, and the Item separator. Here, a comma.
Now the data will look like this :
1_basic: 28
1_lux: 178
2_uni: 16
2_ada_a: 30
2_ada_c: 3
2_sch: 75
Each line being a row
This format is almost the same as a 2 column CSV using ":" as column separator.
tExtractDelimitedFields - Split key value
The first step is to define the output schema.

The desired schema has two fields : key and value. I named them "card_id" and "number_of_cards".
Note that "number_of_cards" is set as an Integer (which it is ^^ ).

Final configuration is to set "Field separator" as ":".
We now have a dataflow looking like this :
| card_id | number_of_cards |
|---|---|
| 1_basic | 28 |
| 1_lux | 178 |
| 2_uni | 16 |
| 2_ada_a | 30 |
tFileInputExcel - Technologies
I did really cover the many advantages of the metadata, so we'll see another use case here.

As you can see, every field is greyed out, and Property Type is set to "Repository". This means we are using a metadata.
Note that there are two "Repository" drop down box, one labelled "Property Type" and the other "Schema".
This means the excel file metadata has 2 distinct part. The first one ("Property Type") holds the path and the sheet configuration.
The second one ("Schema") holds the schema of the sheet.
To declare a new Excel Metadata, right click on "File Excel" under the "Metadata" node and choose create.
A wizard will take you through four simple steps:
- Naming the metadata
- Configuring the path and selected sheets
- Configuring the file format (encoding, headers, footers...)
- Configuring the schema

By the way, as I left a header row with the column names, Talend can guess the format along with the right column names. There's actually nothing to do at all !

tFilterRow : Keep cards impacting others
I just want the cards that have an impact on other cards. My goal here is to compute the exact effect of a card, taking my own tech card into account, so I filter to keep only the line with a "impacts_id" not null (the green column in the first screenshot).

The simplest way to do it is by using the "Advanced Mode" and write a little Java code.
The syntax is a bit different here. It does not use the name of the incoming flow (here row26).

But instead uses "input_row".
tMap : Map active and techs
Data is prepared so, let's join it to compute the boost for each card.
This step would be simpler without the 'Advanced Prayer' card which can be stacked.
For each tech card, we need to check if we own at least one, and if it is stackable.
Yet, 'Advanced Prayer' can only be stacked 10 times, so here's how I proceeded

First, join the tech cards with the active cards. It's an inner join to filter out the cards I don't own.
Second, create a intermediate variable (in the center) to take the max stackability into account (it's 1 if not stackable).
active_cards.number_of_cards > tech_cards.stackable ? tech_cards.stackable : active_cards.number_of_cards
This code just set a max upper value for "number of cards". I called it "card_effect_multiplier". It will be 1 everywhere, expect for "Advanced Prayer" where it will be 10 max, or "number_of_cards" if it's less or eaqul to 10. With this code, I'm ready for a new set of stackable cards in the future.
In the end, I just multiply the effect by the multiplier.

tAggregateRow : aggregate boosts
This component does the same job as a "group by" clause in SQL.

I realised that certain cards were impacted by several tech cards. It's important to group the effects using the "impacts_id" key.
If we don't do that, we will multiply the lines when joining them.
We do a "sum" on all field, except "id" where I chose a list. In fact, we don't even need the card id, the "impact_id" is the only useful key. I kept it for test purpose.
Tip : the number of lines here is VERY small, around 30 or 40. Keeping unnecessary data has absolutely no impact on the flow execution. But, if you were to handle several millions of lines, you would be well advised to drop any unnecessary column as soon as possible for max performance.
tHashOutput : Store data in memory
The tHashOutput component is a memory storage. It is useful in several use cases, such as :
- storing and concatening data coming from a parallelized loop
- storing data a the end of a subjob for flow readability purpose
I used it here simply to make the flow clearer, using 2 subjobs.

Mixing data with the original flow
The data is now in a memory store. The original flow looked like this :

Subjobs & OnSubjobOk
From the beginning, you were looking at a Job. A Job is a data flow with several steps. Each job has a starting component and an ending one. The starting component has a green background : it is the dcity_card_definitions in the previous screenshot. The blue background indicates that the whole flow is also a "subjob". If you have only one "subjob", there is no difference with a job.
Now you can drop a new component, without linking it to any of the component in the already existing subjob. This will simply create a new subjob. Without "trigger" link, they will start in parallel.
But you may want your second subjob to start only on certain conditions. Talend has 5 different trigger links :
- OnSubjob OK => Linked subjob will trigger only if the whole initial subjob ended successfuly
- OnSubjob Error => Linked subjob will trigger only if the whole initial subjob ended with an error. It's perfect for error handling
- Run If => Linked subjob will trigger only if a (set of) condition is met (you write the conditions)
- OnComponent OK => Linked subjob will trigger only if the component ended successfuly.
- OnComponent Error => Linked subjob will trigger only if the component ended with an error.
There are many use cases, like sending email on error or success, logging in database, cleanup after an error...
Here, the OnSubjobOk is used solely for clarity purpose.
tHashInput - tech_boosts
It's linked to the "Store data in memory" tHashOutput. There is just to copy the Output component's schema to the Input Component's schema. Sadly it's not yet automatic.

tMap - Map Ask to card definition
The tMap has a lot of changes. There a new input (named row2) and the foreign key is "impact_id", which is linked to row3.id.
The Var object in the middle is there to prevent any null value. To prevent it, each null value is replaced by a 0.
On out9, the tech boost are added to the base stats. The roi_days computation change a bit too :
JAVA
Math.round(Var.price != 0 ? (((Var.income +Var.income_boost) * 365 / Var.price) * 100 ) : 0)
Conclusion
The job runs in 2 or 3 seconds now that I'm home with a fiber connection.

Next step is to take the taxes into account !